Committing to a GitHub repository via the API is a pretty daunting task if you’ve never done it before. Instead of exposing a high-level commit endpoint, the API relegates committing to a gauntlet of low-level methods which mirror what Git does internally when you run commit. While a bit challenging to comprehend at first, as you walk through the steps you’ll see that they’re actually quite logical, and while learning to commit to the API, you’ll simultaneously be learning a bit about how Git works under the covers.
Required reading
This post will be a lot easier to follow if you take a quick look at this article which talks about how Git structures objects. Pay special attention to Figure 9-3, shown here, which shows how Git objects are linked to one another.
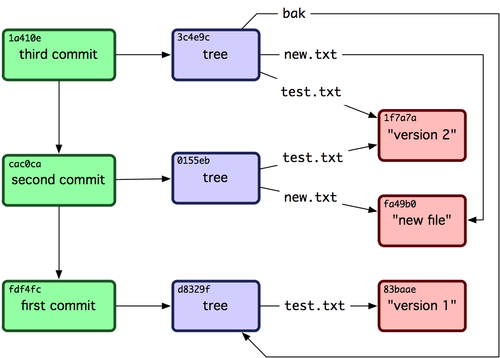
Don’t worry if all this seems a bit confusing. Once we actually start committing a file we’ll be turning the theory into practice, and everything will become a whole lot clearer.
Let’s get started.
1. Get a reference to HEAD
The first thing that you need to do is obtain a reference to your branch’s HEAD. You can do this by making a request to the get reference API endpoint, substituting in heads/[branchname] for :ref in the API documentation. The API will respond with an object that gives you some information on the commit that your branch HEAD points to. Make note of both the SHA and the URL in the response object. We’ll be needing those.
2. Grab the commit that HEAD points to
Take that URL that you grabbed a second ago and make a GET request to it. This will return the commit object that your branch HEAD points to. Commit objects, as shown here, provide us with valuable information on the commit, including the SHA of the commit, and the SHA of the tree that the commit object points to. Note the commit SHA, the tree SHA, and the tree URL.
3. Post your new file to the server
Now it’s time to actually start adding your new file. Start off by posting it to the blobs API endpoint. Your payload must be in the following form.
{
"content": "Content of the blob",
"encoding": "utf-8|base64"
}As you can see, the content can be encoded in either UTF-8, or base 64. In response to your POST, GitHub will respond with information about the blob you uploaded. Take note of the SHA.
4. Get a hold of the tree that the commit points to
To get the tree, simply make a GET request to the tree URL retrieved in step 2. The response will consist of some basic tree information and an array of objects that the tree contains. Make a note of the tree’s SHA.
5. Create a tree containing your new file
The next step is to tell Git where in your repository your new file will live. To do this, you need to construct a tree containing the file(s) you wish to add. You can do this in two ways.
5a. The easy way
Create a tree consisting only of the files that you wish to add or modify, and give GitHub the SHA of the tree that will come before it in your commit history. To perform this step, you’ll need to make a call to the create tree method on the API. The POST payload for a single-file addition/modification looks like the following.
{
"base_tree": "",
"tree": [
{
"path": "",
"mode": "",
"type": "",
"sha": ""
}
]
}Note that mode must be one of 100644 (blob), 100755 (executable), 040000 (subdirectory/tree), 160000 (submodule/commit), or 120000 (blob specifying path of symlink), and that type must be one of "blob", "tree", or "commit".
To add more files to the commit, simply include them in the tree array. The format of tree is exactly the same as the trees returned by the API, so if in doubt regarding the syntax, copy what GitHub sends you when you request a tree from a repository.
While you cannot delete files from your repository using this method, it’s a really neat shortcut if all you want to do is add or modify a few things.
5b. The harder way
Grab a full version of your latest Git tree by appending ?recursive=1 to the tree URL retrieved in step 2, and modify it. When you POST the tree back to the API, simply leave out the base_tree parameter used above.
There two things to be aware of when using this method.
- You must ensure that all of your repository’s files are included in the tree that you POST to the server. Any omissions will not be present (read “deleted”) in your new commit.
- The GET tree API method, as mentioned above, returns a tree that contains subtree objects which describe your repository’s directories. You must remove these objects before posting your tree back to the server. The API will automatically infer your repository’s folder structure by looking at each object’s
pathargument, and if it finds any subtrees in your tree, the API will respond with a500error and no additional information. At the time of writing, the API documentation makes no mention of this peculiarity, which makes it all the more frustrating to come across.
If your POST succeeds, the API will essentially send back the data that you sent to it, and will include the SHA value for the tree that you have just created. Make note of it.
6. Create a new commit
You now have to create a commit which references your new tree. In addition to this, you need to include the SHA(s) of the parent commit(s), as well as a commit message and a small amount of metadata. The entire payload is as follows.
{
"message": "", // Your commit message.
"parents": [""], // Array of SHAs. Usually contains just one SHA.
"tree": "" // SHA of the tree.
}In our specific case you’ll want to put the SHA of the commit that you retrieved in step #2 in the parents array, and the SHA of your newly-created tree from step #5 in the tree field.
The server will in turn respond by giving you the SHA of your new commit.
7. Update HEAD
That’s almost it! We have only one thing left to do. Now that your commit is on the server along with all relevant data, the final step in the process is to move the HEAD reference on your branch up to the new commit. Take the SHA that you saved in the last step and plug it into a request to the update reference endpoint. The name of the reference that you’ll have to specify in the request is [branchname]/HEAD.
Executing this command will move the HEAD reference to point to your newly-minted commit. You’re done! Now anybody who pulls the repository will see your new changes taken into account.